Mar 09 2025 3 mins
过去几年里,关于 AI 发展下一个周期会是什么,人们有很多猜测:Agent(智能体)?Reasoner(推理器)?真正的多模态?
原文链接:vintagedata.org
我认为是时候下定论了:模型即产品。当前研究和市场发展的所有因素都指向这个方向。
- 通用模型的 scaling 正在停滞。这正是 GPT-4.5 发布背后传达的信息:能力在线性增长,而计算成本却呈几何曲线增长。即使过去两年训练和基础设施效率的提升不小,OpenAI 也无法部署这个巨型模型 —— 至少定价远远不是用户能承受的。
- 某些已有方法的训练效果远超预期。强化学习和推理的结合意味着模型突然开始学习任务。这不是机器学习,也不是基础模型,而是一种秘密的第三种东西。甚至是小模型的数学能力也突然变得好得吓人。这让编程模型不再仅仅生成代码,而是自己管理整个代码库。这能让 Claude 在上下文信息很少且没有专门训练的情况下玩《宝可梦》游戏。
- 推理成本急剧下降。DeepSeek 最近的优化意味着所有可用的 GPU 加起来可以支撑全球用户每天让前沿模型输出 10k token。我们现在还远没有这么大的需求。对模型提供商来说,卖 token 赚钱的思路不再有效了:他们必须向价值链的更高处移动。
这也是一个令人不安的方向。所有投资者都在押注应用层。在 AI 进化的下一阶段,应用层可能是最先被自动化和颠覆的。
未来模型的形态
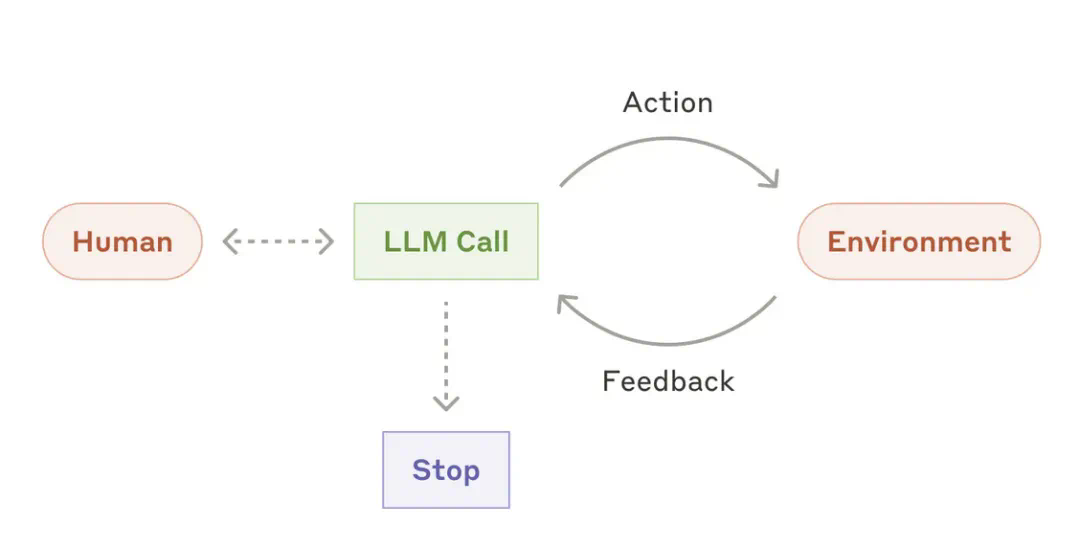
如果模型即产品,单打独斗的开发方式将不再可行。搜索和代码领域是容易摘取的果实:作为过去两年的主要应用场景,市场已接近成熟,你可以在几个月内推出新的 cursor 产品。然而,未来许多最具盈利潜力的 AI 应用场景尚未发展到这一阶段 —— 想想那些仍然主导全球经济大部分的基于规则的系统。拥有跨领域专业知识和高度专注的小型团队可能最适合解决这些问题 —— 最终在完成基础工作后成为潜在的收购对象。我们可能会在 UI 领域看到类似的发展路径:一些优先合作伙伴获得闭源专业模型的独家 API 访问权,前提是他们为未来的业务收购做好准备。
至今我还没有提及 DeepSeek 或中国的实验室。原因很简单,DeepSeek 已经更进一步:它不仅是作为产品的模型,而是作为通用基础设施层。与 OpenAI 和 Anthropic 一样,梁文锋公开了他的计划:
我们认为当前阶段是技术创新的爆发期,而不是应用的爆发期 (...)如果能形成完整的产业上下游,我们就没必要自己做应用。当然,如果需要,我们做应用也没障碍,但研究和技术创新永远是我们第一优先级。
在这个阶段,仅专注于应用开发就像是「用上一场战争的将军打下一场战争」。恐怕许多人甚至还没意识到,上一场战争已经结束了。

体验链接:www.aippt.cn
本期主播:蛋酥酥/猫猫
后期:丹尼播客制作
制作人:蛋酥酥
录制支持:KUEENDOM
粉丝群微信:luxnirvana(备注播客过来哒)