Feb 01 2025 18 mins 1
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。
今天的主题是:
Towards Generalist Robot Policies: What Matters in Building Vision-Language-Action Models
Summary
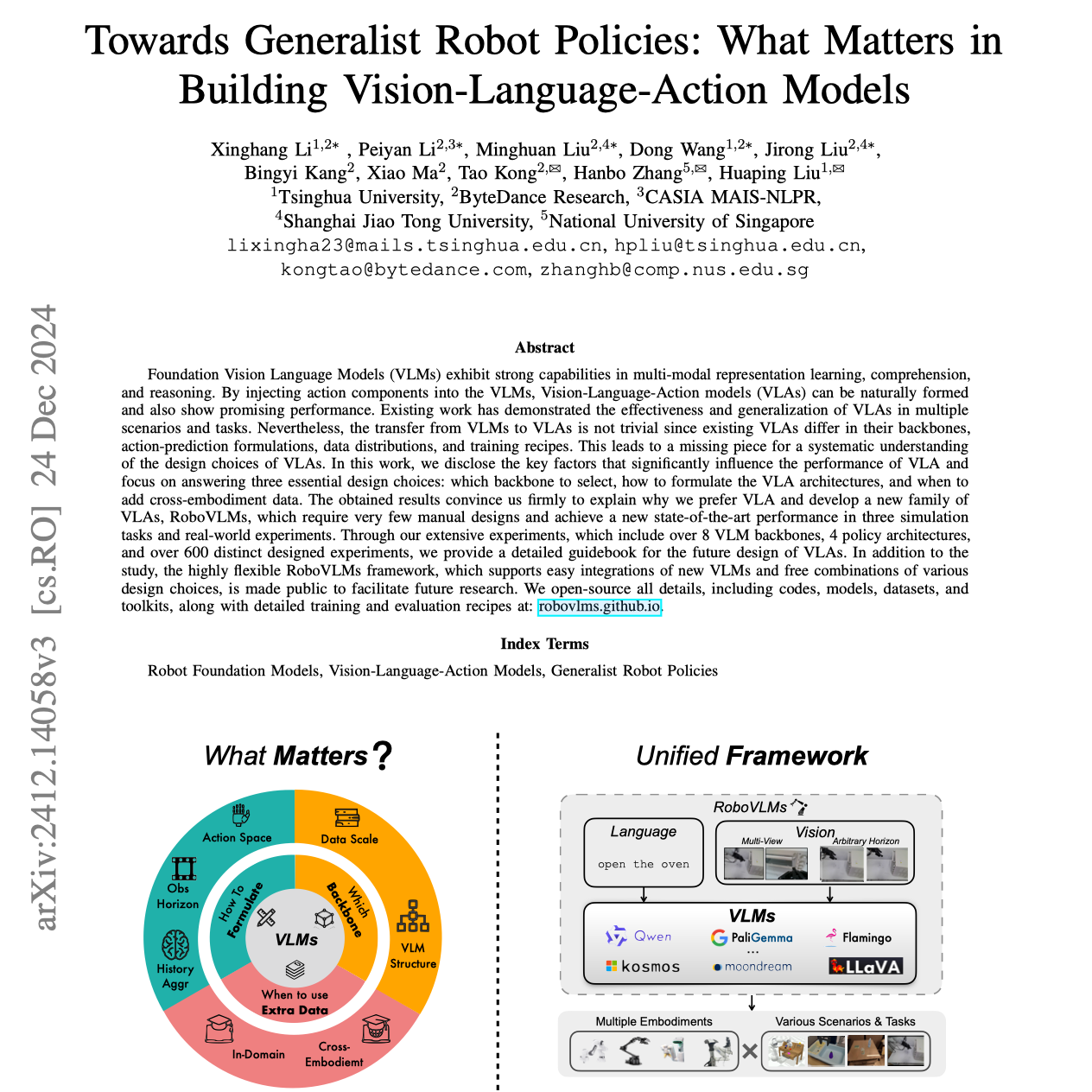
This research paper explores the creation of Vision-Language-Action (VLA) models for generalist robot control. The authors investigate key design choices in VLAs, including the selection of Vision-Language Model (VLM) backbones, optimal VLA architectures, and the effective use of cross-embodiment data. Through extensive experimentation, they identify superior VLA structures and backbones, achieving state-of-the-art performance on simulated and real-world robotic tasks. A new framework, RoboVLMs, is introduced to simplify the process of creating VLAs and is made publicly available. The findings highlight the significant advantages of VLMs for generalist robot policies and offer valuable guidance for future VLA development.
本研究探讨了面向通用机器人控制的视觉-语言-行动(Vision-Language-Action, VLA)模型的创建。作者研究了 VLA 的关键设计选择,包括视觉-语言模型(Vision-Language Model, VLM)骨干网的选择、最优 VLA 架构,以及跨体态数据的有效使用。通过大量实验,他们确定了优越的 VLA 结构和骨干网,在模拟和实际机器人任务中达到了最先进的性能。研究还提出了一个新框架 RoboVLMs,简化了创建 VLA 的过程,并公开发布。研究结果强调了 VLM 在通用机器人策略中的显著优势,并为未来 VLA 的发展提供了宝贵的指导。
原文链接:https://arxiv.org/abs/2412.14058

